Lending Club Default Classification(Kor.)
Lending Club Default Fully Paid Classification Model
- Contributors:
Jang, Sungguk(simfeel87@gmail.com)
Kim, Gibeom(curtisk808@gmail.com)
Shin, Yoonsig(shinys825@gmail.com)
-
JAN 18 2017 ~ MAR 16 2017
-
Raw data from Lending Club Loan Data & Kaggle
-
Github repository:
Objective
- How to build a basic strategy for beginners
-
P2P 투자시 은행보다 좋은 수익률을 얻으면서 최대한 자신의 원금을 보존하기위해 고안된 모델을 이용하여 중요 정보를 얻는다.
 {width=”3.7069444444444444in”
height=”3.691666666666667in”}Motivation
{width=”3.7069444444444444in”
height=”3.691666666666667in”}Motivation
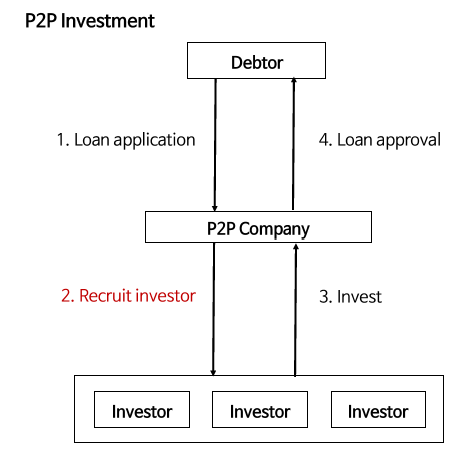
투자자는 위의 그림1과 같이 P2P 회사로부터 제공받은 Debtor의 정보를 이용하여 투자를 결정을 한다. 이때, P2P 회사는 은행의 lending programs 보다 낮은 금액으로 운영하고, 저금리 형태로 대출자에게 돈을 제공하며, solid한 수익모델을 투자자에게 전달한다. 최근 P2P 형태의 대출이 매우 빠르게 증가하고 있으나 투자 위험 관리를 P2P 업체의 정보에만 의존해야 하므로 투자자의 위험부담이 커지고 있다. 투자자에게 보다 solid 한 투자정보를 제공하기 위해 Lending club 이 제공하는 데이터를 이용하여 프로젝트를 수행하게 되었다.
Pre-Processing
-
887,376건의 데이터중 feature 74개를 대출 시점에 파악 불가능한 항목, 특정변수의 하위항목, 현재 상환중인 채권 의 데이터를 고려하여 268,137건의 데이터와 변수 27개로 전처리
-
변수확인(독립/종속 변수의 정의, 변수의 유형;범주형, 연속형, 데이터타입 확인), Raw데이터 확인(단변수 분석, 이변수 분석)
-
Missing value treatment 및 Outlier treatment
-
Feature Engineering (Scaling, Dummy)
-
 {width=”4.645215441819772in”
height=”3.6233770778652667in”}Under Sampling
{width=”4.645215441819772in”
height=”3.6233770778652667in”}Under Sampling
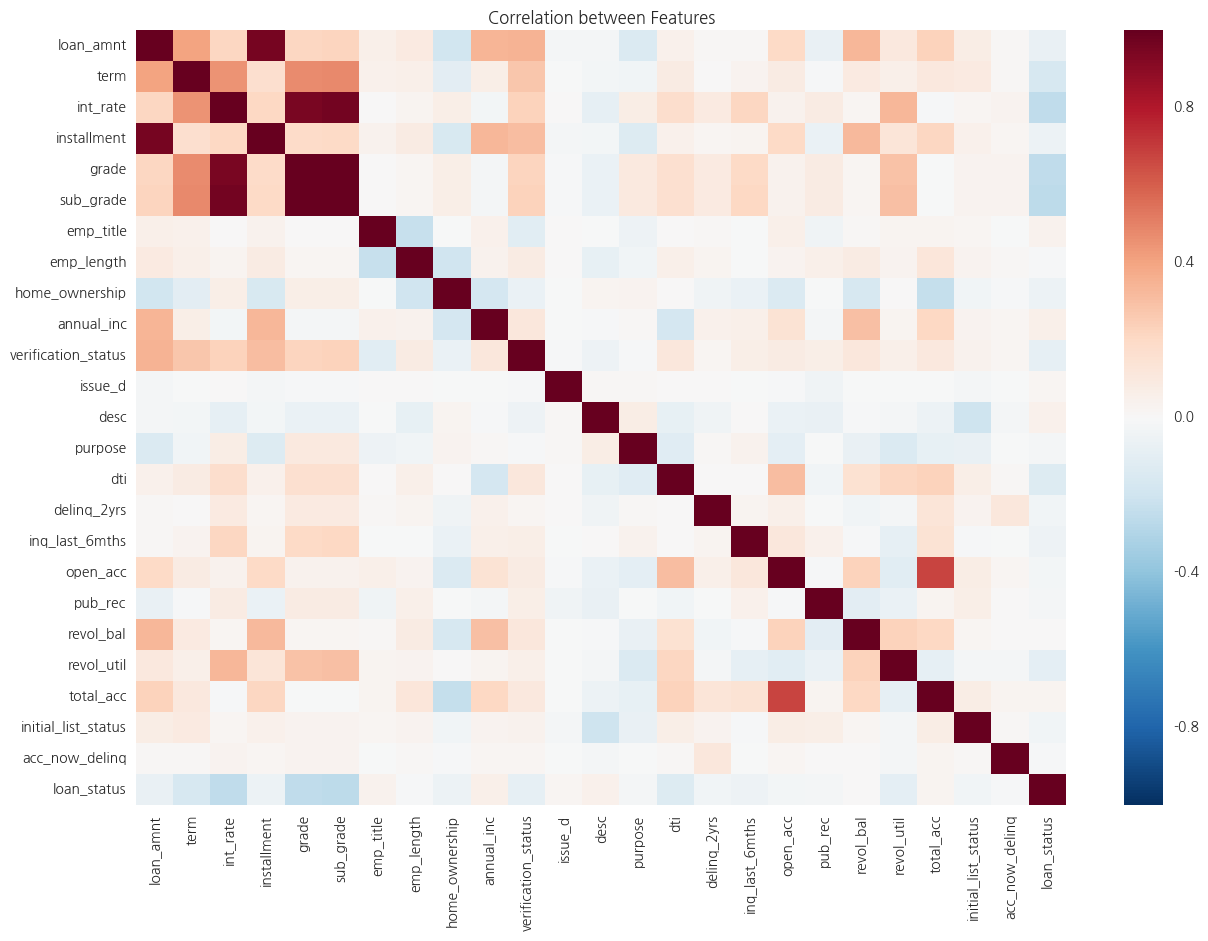
그림2는 features간에 상관관계를 heat map을 통해 시각적으로 보여준다. 높은 상관관계를 가지고 있는 features를 분류하여 제거한다.
그림3과 그림4는 QQ plot을 통해 outlier 가 있는 features 와 features의 분포상태를 간접적으로 보여주며 그림4는 outlier 제거,scaling 및 transform 을 한 features의 QQ plot을 보여준다.
 {width=”4.34375in”
height=”2.9479166666666665in”}
{width=”4.34375in”
height=”2.9479166666666665in”}
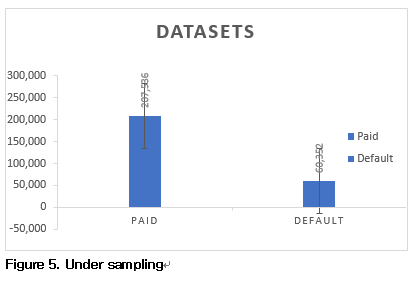
그림5 는 총 데이터 중 Default 데이터의 양이 fully paid 의 데이터양 보다 적어 under sampling이 필요한 이유를 설명해 준다. Random 하게 fully paid 의 데이터를 default의 데이터 개수와 동일하게 데이터를 추출하여 이를 train 과 test데이터 set으로 나누어 모델링하고 이를 전체 데이터를 이용한 모델링과 비교한다.
Model fit and scoring
- SGD CV Accuracy for under sampled datasets
Average Accuracy: 0.59
- SGD CV Accuracy for whole datasets
Average Accuracy: 0.75
- LDA CV Accuracy for under sampled datasets
Average Accuracy: 0.59
- LDA CV Accuracy for whole datasets
Average Accuracy: 0.75
- Logistic Regression CV Accuracy for under sampled datasets
Average Accuracy: 0.59
- Logistic Regression CV Accuracy for whole datasets
Average Accuracy: 0.75
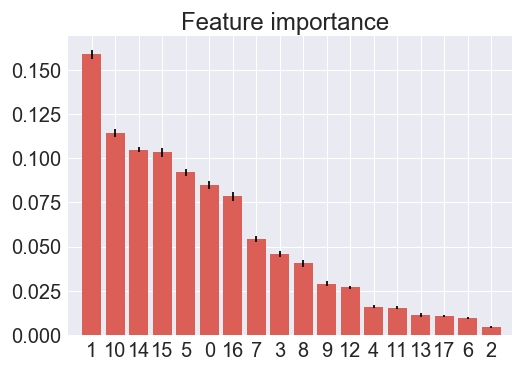
SGD, LDA, and Logistic Regression 을 이용해 각각 datasets으로 모델링을 해 보았다. 각 모델링의 성능이 기대치 보다 낮았기 때문에, default 에 영향을 미치는 특정 features를 찾기 위해 Random Forest를 통한 Feature importance 과 features transform 과정을 수행하였다.
- Random Forest Features importance
 {width=”3.392361111111111in” height=”2.54375in”}
{width=”3.392361111111111in” height=”2.54375in”}
-
Loan amount(1)
-
Interest rate(10)
-
Job title(14)
-
Employment length in years(15)
-
Home ownership status(5)
-
Annual income(0)
-
Income verification status(16)
-
Optimization using Logistic Regression and Features Transform
-
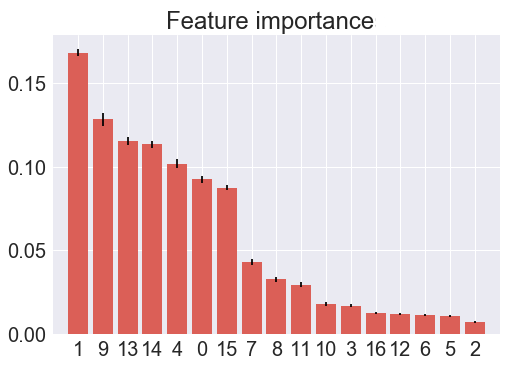 {width=”3.313888888888889in”
height=”2.439583333333333in”}Loan amount(1)
{width=”3.313888888888889in”
height=”2.439583333333333in”}Loan amount(1) -
Interest rate(9)
-
Job title(13)
-
Home ownership status(14)
-
Annual income(4)
-
Income verification status(0)
-
Issued month(15)
-
-
Logistic Regression using important features
{width=”3.2597222222222224in” height=”2.34375in”}
-
Job title(5)
-
Issued month(6)
-
Income verification status(4)
-
Home ownership status(3)
-
Loan amount(1)
-
Interest rate(2)
-
Annual income(0)
- Random Forest Classifier Confusion Matrix
Conclusion
위에서 제공한 전체 Process를 통해서 다음과 같은 의미 있는 결론을 도출하였다. beginner 입장에서 최소한의 원금 보존을 위해서는 다음과 같은 Debtors의 features를 고려해야 한다.
-
Debtor’s high annual incomes
-
Debtor’s low interest rate
-
Debtor’s job title(opened or not)
-
Debtor’s issued month(JAN, SEP, DEP)
-
Debtor’s income verification status
-
Debtor’s house ownership
Insight
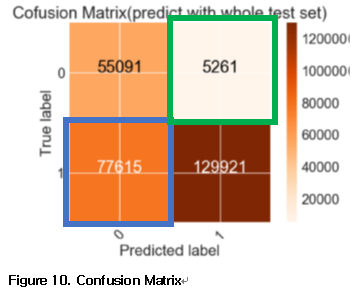 {width=”3.7083333333333335in”
height=”3.0104166666666665in”}
{width=”3.7083333333333335in”
height=”3.0104166666666665in”}
(True 1, Predict 0)은 Lose Opportunity를 의미한다. 즉, 원금에 변화는 없으면서 단순히 돈을 얻을 기회를 놓친 것이다. 투자자의 입장에서는 직접 투자를 하지 않았기 때문에 직접 영향을 미치는 값이 아니다.
(True 0, Predict 1)은 실제 돈을 잃는 것을 의미한다. 즉, 투자자가 Debtor가 돈을 값을 것이라고 예상 했지만 값지 않은 경우이며 투자자에게 직접적으로 손실을 가져오는 값이다.
위의 그림 10. 은 optimized 된 features를 이용하여 Random Forest Classifier를 모델로 한 결과 이다. 이 프로젝트의 과정을 통해 얻은 insight를 위의 설명을 이용하여 설명을 하면 다음과 같다.
한 투자자가13%의 interest rate을 갖고 발행된 267888개의 채권에 모두 $1씩 투자한다고 가정을 하면 프로젝트의 모델을 사용했을 경우 투자한 총금액에서 $16,889.73 이득을 취하게 되고 $5261 을 잃게 된다. 즉 $11,628.73 의 이득을 취하게 된다. 이는 투자한 금액에 약 9%에 해당하는 값이 된다.
**프로젝트를 마치며, **
팀프로젝트를 수행하면서 데이터 분석을 하기 위해서는 Raw data와 pre-processing의 중요성을 느끼게 되었다. Lending club datasets 역시 raw data라고 하기보다는 한번 Lending club에 의해서 filtering 된 datasets이다. 따라서 models의 performance값이 팀에서 원하는 성능을 보여주지 못하였던 것 같다. 하지만 이 분석을 통해서 투자자의 입장에서 고려하면 중요한 insight를 얻어 낼 수 있었다. 이와 같이, 데이터를 분석함에 있어서 다양한 시각에서의 의미를 얻어내는 넓은 관점이 필요하다고 볼 수 있다. 데이터 분석 프로젝트를 처음 수행함에 있어서 팀원 들과의 자유로운 의사소통이 프로젝트를 마무리 할 수 있게 한 중요한 요소였다. 또한 훌륭한 팀원들 덕택에 프로젝트를 진행하면서 데이터 분석에 대해서 많이 배울 수 있었다.